
Using Gradient Descent to An Optimization Algorithm that uses the Optimal Value of Parameters (Coefficients) for a Differentiable Function
DOI:
https://doi.org/10.17762/ijcnis.v15i1.5718Keywords:
Gradient descent, optimisation algorithm, deep network optimisation; adaptive gradient descent; batch sizeAbstract
Deep neural networks (DNN) are commonly employed. Deep networks' many parameters require extensive training. Complex optimizers with multiple hyper parameters speed up network training and increase generalisation. Complex optimizer hyper parameter tuning is generally trial-and-error. In this study, we visually assess the distinct contributions of training samples to a parameter update. Adaptive stochastic gradient descent is a variation of batch stochastic gradient descent for neural networks using ReLU in hidden layers (aSGD). It involves the mean effective gradient as the genuine slope for boundary changes, in contrast to earlier procedures. Experiments on MNIST show that aSGD speeds up DNN optimization and improves accuracy without added hyper parameters. Experiments on synthetic datasets demonstrate it can locate redundant nodes, which helps model compression.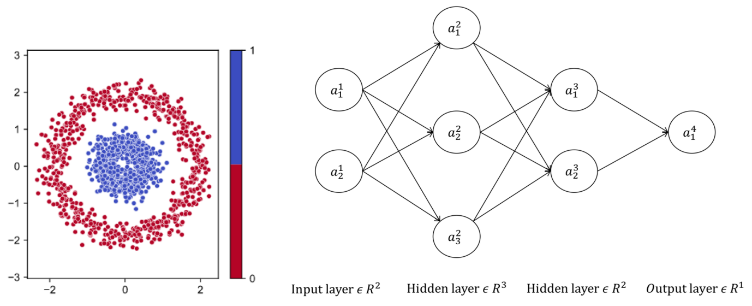
Downloads
Published
2023-06-07
How to Cite
Abdulazeez, F. A. ., Ismail, A. S. ., & S. Abdulaziz, R. . (2023). Using Gradient Descent to An Optimization Algorithm that uses the Optimal Value of Parameters (Coefficients) for a Differentiable Function. International Journal of Communication Networks and Information Security (IJCNIS), 15(1), 24–36. https://doi.org/10.17762/ijcnis.v15i1.5718
Issue
Section
Research Articles
License
Copyright (c) 2023 International Journal of Communication Networks and Information Security (IJCNIS)

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

